CryptexLLM. Reprogramming LLMs for Financial Time Series Forecasting.
View on GitHubProject Overview
CryptexLLM represents a groundbreaking approach to financial time series forecasting by "reprogramming" Large Language Models (LLMs) to enhance their generalizability beyond traditional language tasks. Drawing inspiration from the original TimeLLM framework, it bridges the worlds of natural language processing and quantitative finance.
This project explores how LLMs can be used to recognize patterns in financial data and anticipate market behavior — opening up new possibilities for understanding trends, volatility, and sentiment.
Technical Architecture
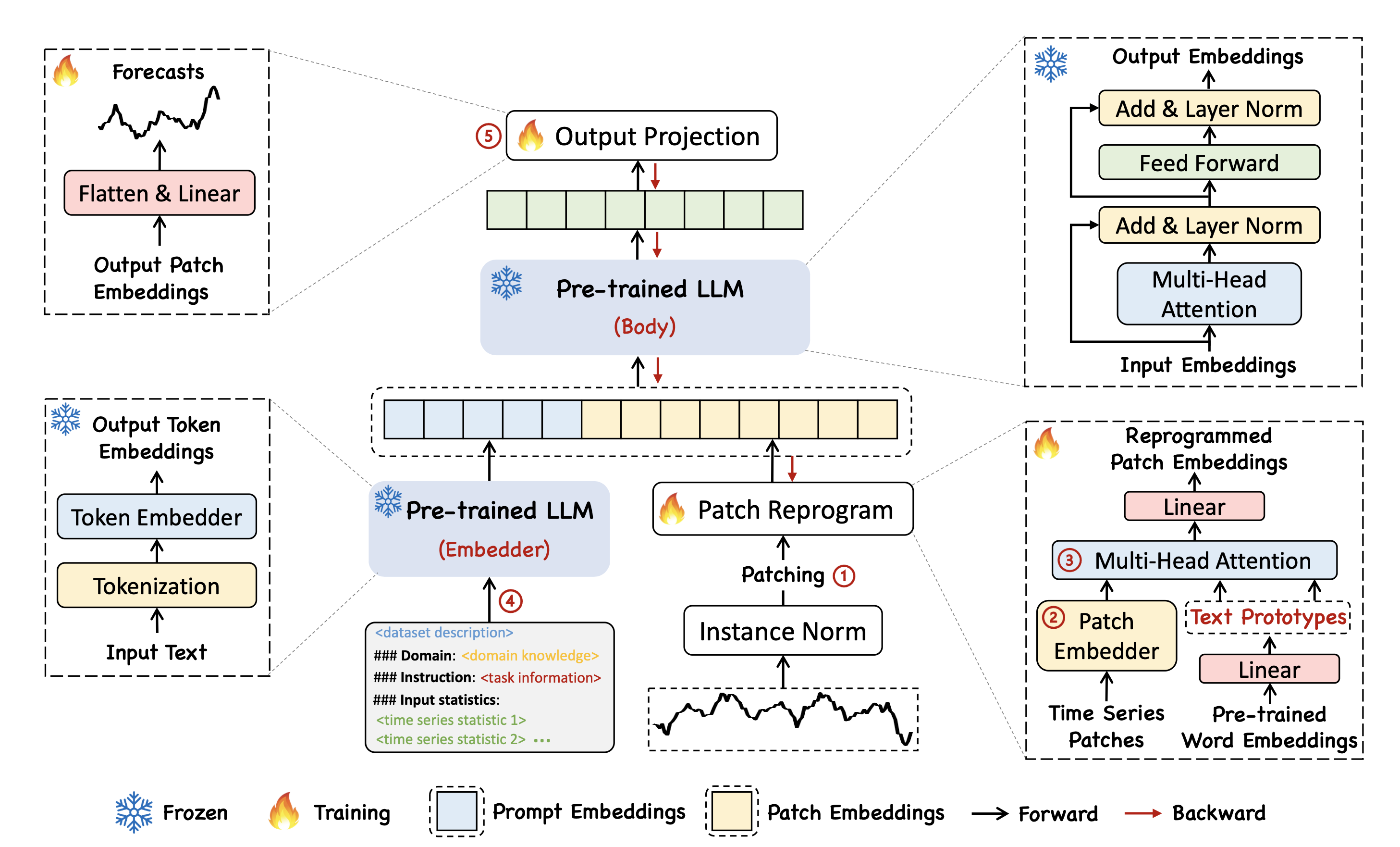
Patch "Reprogramming"
Time series data is broken down into smaller segments, or "patches," with each patch treated like a word the language model can understand. This makes it easier for the model to process long sequences of financial data while still preserving the order and timing of events.
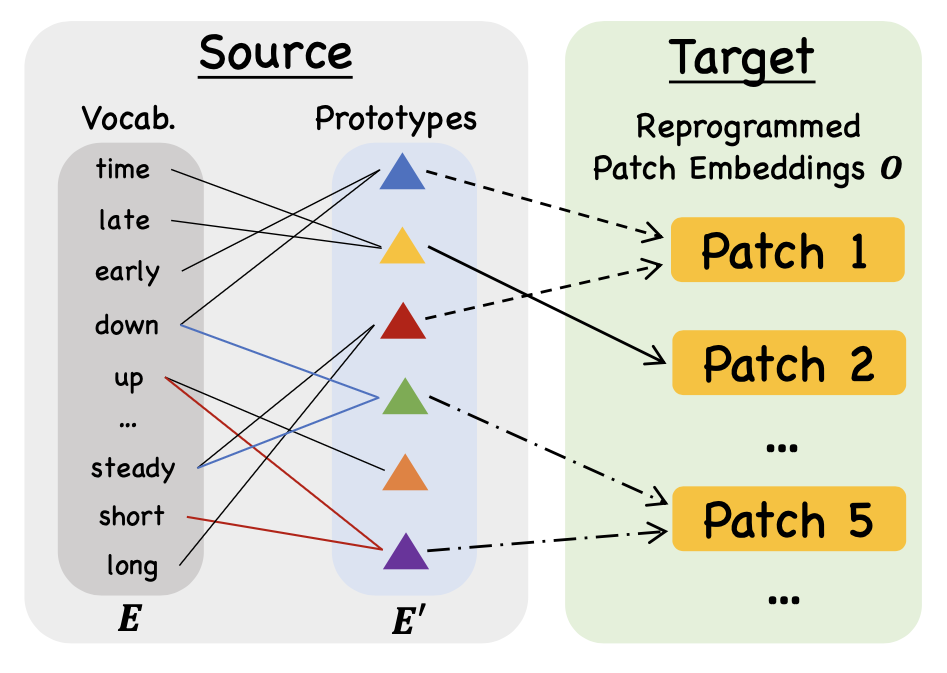
Patch "Reprogramming"
This approach reimagines financial forecasting by treating market data like language. Each segment carries meaning, allowing the model to read trends and patterns as if following a financial story.
- Breaks time series data into smaller, meaningful segments
- Maps each patch to vocabulary tokens for LLM processing
- Keeps the order and timing of events intact
- Makes it possible to analyze long stretches of financial data efficiently
Prompt-as-Prefix
Our method keeps the original LLM weights unchanged and instead learns how to format the inputs and outputs. It also adds positional embeddings to maintain the sequence of events, allowing the model to understand time without losing its core abilities.

Prompt-as-Prefix
By keeping the pre-trained weights unchanged, we retain the LLM’s existing knowledge while adapting it to financial forecasting using small, trainable layers.
- Provides contextual guidance
- Bridges numerical data and language models
- Supports flexibility without fine-tuning
- Improves interpretability and directional accuracy
Normalization
CryptexLLM uses reversible normalization to make financial data easier for the model to learn from. The data is scaled before prediction and then converted back to its original form for meaningful results.
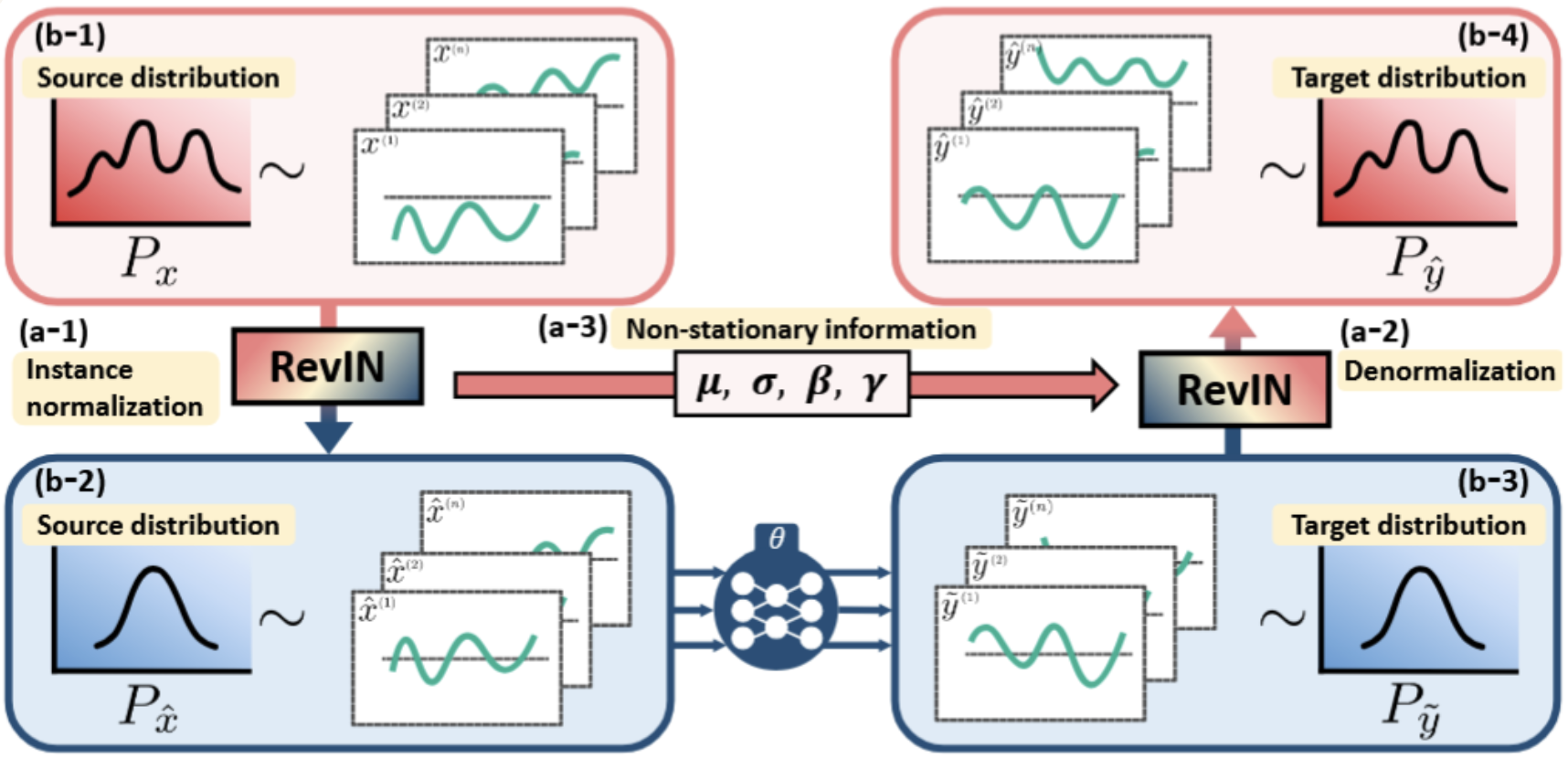
Normalization
Normalization works by standardizing each input using its own mean and variance, then restoring the original scale after prediction — helping the model stay robust to shifting market conditions.
- Stabilizes noisy financial data for better pattern recognition
- Adapts to shifting market conditions
- Restores original scale after prediction for interpretability
- Uses instance-specific mean and variance for precise normalization
Cryptex Dataset
The Cryptex dataset contains high-resolution OHLCV data for the BTC-USDT pair from Binance.us, spanning September 2019 to May 2024. It supports forecasting at multiple time scales — from daily to second-level granularity — enabling flexible analysis of both short- and long-term trends.
Data Source
▼The financial data used in CryptexLLM is sourced from Yahoo Finance, a widely trusted platform for market information. Historical Bitcoin (BTC) data is utilized, including standard OHLCV metrics — Open, High, Low, Close prices, and trading Volume.
Granularity
▼Data is processed at multiple resolutions — daily, hourly, by the minute, and down to the second — depending on the forecasting task. This multi-scale setup allows the model to be evaluated across both long-term trends and high-frequency market movements.
Timestamp Format
▼Each record is tagged with a Unix timestamp, enabling precise alignment with sentiment data, volatility measures, and other time-dependent inputs.
Preprocessing & Variants
▼To ensure data quality and adaptability, missing values are cleaned or filled during preprocessing.
Training
The original project training process involves several key hyperparameters that control the model's behavior and performance:
- seq_len: Input sequence length.
- label_len: Label length.
- pred_len: Output prediction window.
- features: Forecasting task. Options: M for multivariate predict multivariate, S for univariate predict univariate, and MS for multivariate predict univariate.
- patch_len: Patch length. 16 by default, reduce for short term tasks.
- stride: Stride for patching. 8 by default, reduce for short term tasks.
Inference
Once the model is trained, CryptexLLM offers two types of forecasting to generate predictions:
🎯 Standard Forecasting
Predicts future values directly from the end of your data
bash ./scripts/inference.sh
What it does: Takes your historical data and predicts what happens next
Output: Predictions displayed in terminal
🔄 Autoregressive Forecasting
Generates multiple overlapping predictions for robust forecasting
bash ./scripts/inference_ar.sh
What it does: Creates multiple predictions using sliding windows
Output: Detailed CSV file with all predictions
How Autoregressive Forecasting Works
Our Work
Enhanced Feature Engineering
▼Captures:
📈 Momentum & Trends
SMA, EMA, RSI, MACD
📊 Volatility
Bollinger Bands, GARCH, ATR
💹 Market Behavior
VWAP, MFI, lag features
🕒 Time Features
Hour, Day-of-Week, cyclical patterns
Built into feature_engineering.py
Correlation-Based Feature Selection
▼⚙️ Step-by-step process:
Rank by correlation with BTC price
Remove highly similar features (correlation > 0.9)
Score with Pearson, Mutual Info, F-statistic
Select top 20 — used in every training run
Faster training
5.2× speedup
Lighter memory load
~70% reduction
Adaptive Loss Functions
▼Smarter training through dynamic loss combination
The Problem
- Fixed loss functions (like MSE) miss key signals
- Manual tuning is slow and inconsistent
- No one-size-fits-all for crypto forecasting
Our Solution
- Learnable weighting of multiple losses
- Combines MSE, DLF, Trading Loss, MADL, etc.
- Adapts weights during training based on performance
- Outperforms any single loss by +89.8%
Why It Works
- Automatically finds the best loss combo
- Supports 5 pre-defined strategies (e.g., Trading Focused, Robust)
- No manual tuning — just better results, faster
External Data Integration
▼From simulated patterns to real-time market insight
Before vs After
Architecture Highlights
API Integration
- RedditSentimentAPI() – r/Bitcoin, r/cryptocurrency
- FearGreedIndexAPI() – Daily crypto market sentiment
- NewsAPISentiment() – Multiple sources via NewsAPI
Data Processing Pipeline
- Reddit/News → Daily sentiment scores
- Fear & Greed → Normalized index (0–1)
- All fused via weighted average (30/30/40)
Domain-Specific Prompting
▼Turning CryptexLLM into a market-aware system
What We Built
Dynamic prompts tailored to:
Supports enhanced datasets:
Hyperparameter Sweep
▼Systematic tuning for peak CryptexLLM performance
🎯 Goal: Identify optimal settings across model, prompt, and training configurations
🔍 Swept: Model types, sequence lengths (2-168), loss functions (MSE, DLF, MADL, Trading Loss), prompt templates, prediction horizons (1-7), layer counts
⚙️ Setup: Auto-logging of loss, accuracy, and inference time to NFS server
Model performance correlation analysis across different hyperparameter configurations
MLFlow & Optuna Integration
▼Automated tracking & optimization for CryptexLLM
What We Added
MLFlow Autologging
- Tracks hyperparameters, metrics, and model artifacts
- Can also log sentiment API settings (Reddit, News, Fear & Greed)
- Stores trained models with full metadata
Optuna Optimization
- Smart hyperparameter search with TPE
- Early stopping for inefficient trials
- Fine-tunes sentiment weights & model settings
- Generates importance plots and optimization history
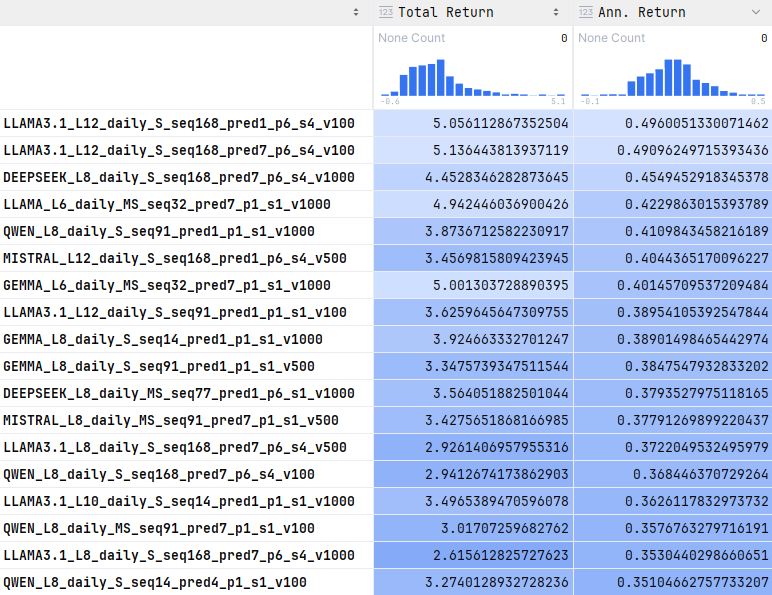
Backtesting
▼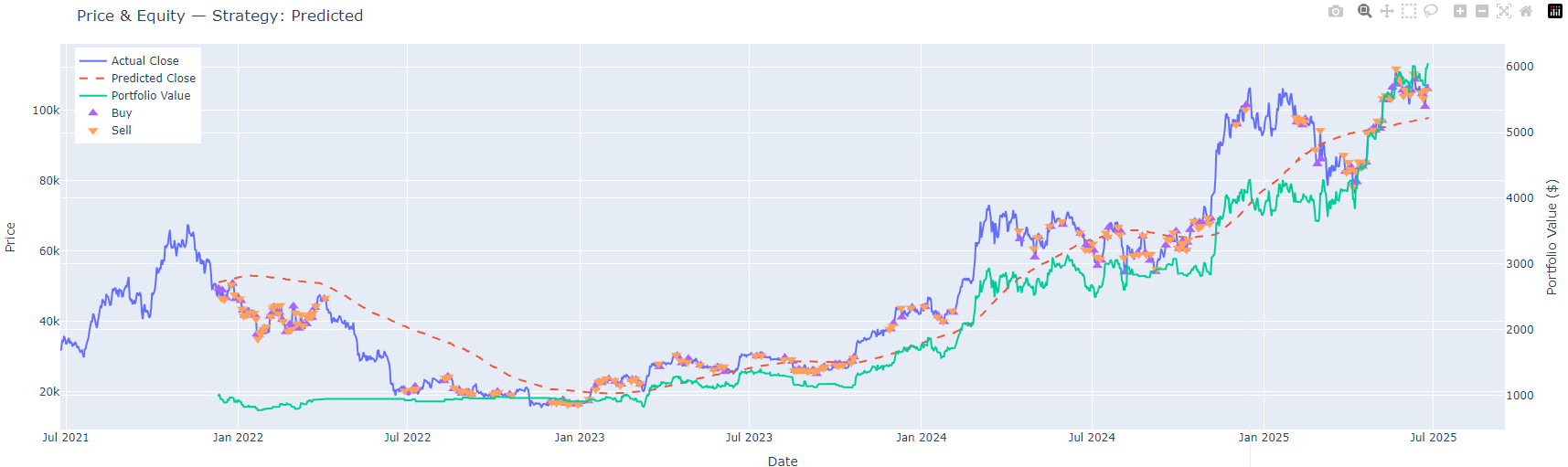
Backtesting analysis across multiple LLM models and trading strategies
Models: DEEPSEEK, LLAMA3.1, QWEN, MISTRAL, GEMMA, LLAMA
Strategies: Prediction-based, Directional, Momentum, Buy & Hold benchmark
Metrics: Sharpe Ratio, Max Drawdown, Win Rate, Total Return with professional analysis
Output: Interactive visualizations, detailed reports, institutional-grade analytics
Team

Anwar
From Casablanca, Morocco
Master's in AI at Illinois Institute of Technology
Upcoming PhD student in Computer Science at IIT

Mary
From New York City
Upcoming 4th Year at Fordham University
Major in Computer Science

Logan
From Suburbs of Chicago
Upcoming 4th Year at Illinois Institute of Technology
Major in Data Science
FAQ
Is the code open source?
Yes, CryptexLLM is available as an open-source project with complete documentation.
What makes CryptexLLM different from traditional forecasting models?
CryptexLLM leverages the contextual understanding capabilities of Large Language Models, allowing it to interpret financial data within broader market narratives and economic contexts, rather than relying solely on numerical patterns.
What is Patch Reprogramming?
Patch Reprogramming converts continuous time series into small, semantically meaningful “patches,” which act like words in a sentence. These patches are then processed by LLMs as if reading a story, preserving the temporal structure of financial data while enabling the use of language-based models.
Do you retrain LLMs like LLaMA or DeepSeek from scratch?
No. CryptexLLM keeps pre-trained LLM weights frozen and instead reprograms the input and output using lightweight, learnable projection layers. This dramatically reduces training costs while leveraging generalizability of large-scale language models.
What hardware requirements are needed?
CryptexLLM can run on standard GPUs with at least 8GB VRAM for optimal performance.
How does the model handle market volatility and sudden changes?
The model incorporates advanced risk-aware loss functions and multi-scale architecture to adapt to market volatility. It uses correlation-based feature selection to identify the most relevant indicators during different market conditions.
Can I integrate external data sources?
Yes, CryptexLLM supports external data integration including news sentiment, market indicators, and macroeconomic data to enhance predictions.
How long does training take?
Training time varies from a few hours to several days depending on dataset size and hardware.
Is CryptexLLM suitable for production or just research?
While CryptexLLM is a research prototype, it’s designed with production-readiness in mind. It includes automated tracking via MLFlow, hyperparameter optimization with Optuna, and efficient feature selection pipelines. These components make it scalable and adaptable for future real-world deployment.